卷积神经网络
LeNet
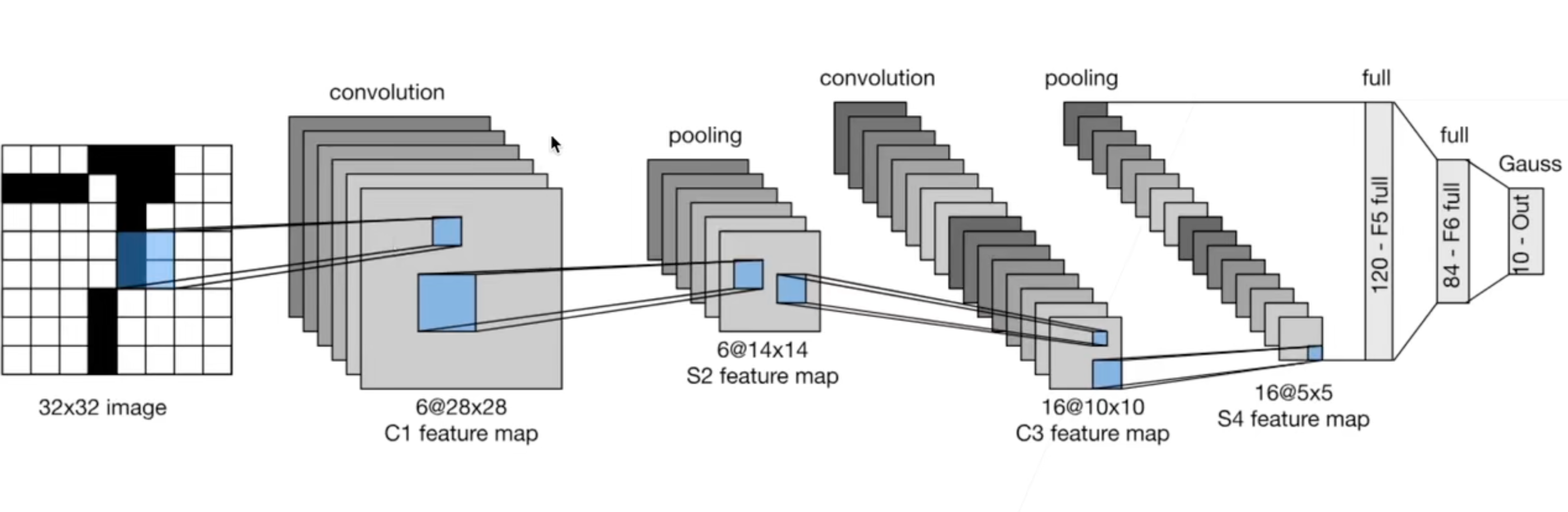
-
由两个卷积层,两个池化层,两个全连接层组成
-
首次应用在手写数字识别上,取到了不错的成果,并留下了著名的 MNIST 数据集
实现
import torch
from torch import nn
import torchvision
from torchvision import datasets, transforms
from torch.utils import data
import matplotlib.pyplot as plt
import numpy as np
transform = transforms.ToTensor()
data_train = datasets.MNIST(root = "./data/",
transform=transform,
train = True,
download = True)
data_test = datasets.MNIST(root="./data/",
transform = transform,
train = False,
download = True)
loader_train = data.DataLoader(dataset = data_train, batch_size = 100, shuffle = True)
loader_test = data.DataLoader(dataset = data_test, batch_size = 100, shuffle = True)
# 展示图片和标签
def show_images(images, rows, colums, labels):
img = torchvision.utils.make_grid(images, nrow=colums, ncolum=rows)
img = img.numpy().transpose(1, 2, 0)
plt.imshow(img)
plt.show()
print("labels: \n", labels.reshape((rows, colums)))
def accuracy(y_hat, y):
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.max(axis=1)[1] # 将概率(值)转换成标签
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
images, labels = next(iter(loader_train))
show_images(images, 10, 10, labels)
print("accuracy: \t", accuracy(labels, labels) / len(labels))

labels:
tensor([[1, 1, 1, 2, 4, 8, 6, 1, 2, 4],
[1, 1, 7, 1, 9, 0, 1, 8, 9, 2],
[1, 4, 9, 2, 1, 6, 6, 7, 1, 9],
[4, 5, 5, 8, 5, 1, 5, 9, 6, 0],
[9, 5, 3, 9, 0, 3, 2, 5, 6, 4],
[6, 9, 7, 1, 0, 2, 2, 0, 2, 2],
[9, 7, 3, 0, 7, 1, 5, 8, 5, 0],
[5, 0, 6, 4, 9, 2, 9, 2, 5, 2],
[8, 5, 8, 2, 3, 6, 8, 0, 2, 4],
[5, 6, 6, 5, 1, 2, 1, 4, 2, 4]])
accuracy: 1.0
class Padding(nn.Module):
def forward(self, X):
return X.view(-1, 1, 28, 28)
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net = nn.Sequential(
Padding(), nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(), # 当年使用的就是 Sigmoid 激活函数
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10)
)
net.apply(init_weights)
Sequential(
(0): Padding()
(1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(2): Sigmoid()
(3): AvgPool2d(kernel_size=2, stride=2, padding=0)
(4): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(5): Sigmoid()
(6): AvgPool2d(kernel_size=2, stride=2, padding=0)
(7): Flatten(start_dim=1, end_dim=-1)
(8): Linear(in_features=400, out_features=120, bias=True)
(9): Sigmoid()
(10): Linear(in_features=120, out_features=84, bias=True)
(11): Sigmoid()
(12): Linear(in_features=84, out_features=10, bias=True)
)
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=0.5)
epochs = 16
l_train = []
a_train = []
a_test = []
for epoch in range(epochs):
loss_epoch = []
accuracy_train_epoch = []
accuracy_test_epoch = []
net.train()
for X, y in loader_train:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
net.eval()
# 评价模型对训练数据集的精度
for X, y in loader_train:
y_hat = net(X)
loss_epoch.append(loss(y_hat, y).sum())
accuracy_train_epoch.append(accuracy(y_hat, y) / len(y))
# 评价模型对验证数据集的精度
for X_test, y_test in loader_test:
y_hat = net(X_test)
accuracy_test = accuracy(y_hat, y_test) / len(y_test)
accuracy_test_epoch.append(accuracy_test)
l = torch.tensor(loss_epoch).mean()
a = torch.tensor(accuracy_train_epoch).mean()
a_t = torch.tensor(accuracy_test_epoch).mean()
print(f"loss {l} train data accuracy {a} test data accuracy {a_t}")
l_train.append(l)
a_train.append(a)
a_test.append(a_t)
loss 2.3035054206848145 train data accuracy 0.09863334149122238 test data accuracy 0.0957999899983406
loss 2.3008360862731934 train data accuracy 0.10218333452939987 test data accuracy 0.10100000351667404
loss 0.5147294402122498 train data accuracy 0.8399333357810974 test data accuracy 0.8406999707221985
loss 0.2823667526245117 train data accuracy 0.9123332500457764 test data accuracy 0.9166000485420227
loss 0.18640278279781342 train data accuracy 0.9432166814804077 test data accuracy 0.9490999579429626
loss 0.14082972705364227 train data accuracy 0.9573500752449036 test data accuracy 0.9613000750541687
loss 0.11830482631921768 train data accuracy 0.9636832475662231 test data accuracy 0.9658999443054199
loss 0.09789104014635086 train data accuracy 0.9697166085243225 test data accuracy 0.9723999500274658
loss 0.09012594074010849 train data accuracy 0.9722166061401367 test data accuracy 0.9735000729560852
loss 0.07697445899248123 train data accuracy 0.9772499799728394 test data accuracy 0.9766000509262085
loss 0.06742171198129654 train data accuracy 0.9795166254043579 test data accuracy 0.9802000522613525
loss 0.06364765763282776 train data accuracy 0.980316698551178 test data accuracy 0.9812000393867493
loss 0.06005176529288292 train data accuracy 0.9821000099182129 test data accuracy 0.9794000387191772
loss 0.05151296779513359 train data accuracy 0.9843997955322266 test data accuracy 0.9825000166893005
loss 0.05150843784213066 train data accuracy 0.9839999675750732 test data accuracy 0.9837999939918518
loss 0.045171719044446945 train data accuracy 0.9866498708724976 test data accuracy 0.9849000573158264
l1, = plt.plot(np.arange(1, epochs+1), np.array(l_train))
l2, = plt.plot(np.arange(1, epochs+1), np.array(a_train))
l3, = plt.plot(np.arange(1, epochs+1), np.array(a_test))
plt.xlabel('epochs')
plt.legend(handles=[l1, l2, l3],labels=['train loss','train accuracy', 'test accuracy'],loc='best')
plt.show()
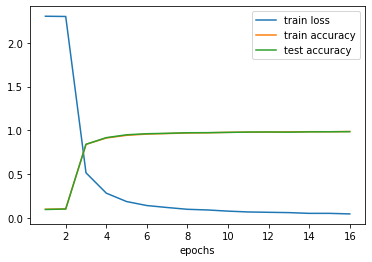
- 没啥明显过拟合现象
- 测试训练集的精度也比 MLP 要高一点
feature, label = next(iter(loader_test))
y_hat = net(feature)
y_hat = y_hat.max(axis=1)[1] # 提取标签
show_images(feature, 10, 10, y_hat)
print("accuracy: ", accuracy(y_hat, label) / len(label))

labels: tensor([[7, 3, 9, 7, 8, 9, 4, 2, 7, 7],
[4, 8, 3, 6, 4, 0, 7, 7, 3, 0],
[0, 7, 7, 8, 1, 2, 5, 8, 8, 1],
[5, 2, 6, 4, 8, 2, 0, 1, 7, 0],
[9, 1, 0, 2, 5, 4, 8, 3, 5, 7],
[4, 7, 9, 6, 5, 0, 2, 7, 1, 1],
[8, 4, 5, 8, 5, 5, 3, 9, 1, 3],
[1, 2, 2, 5, 9, 9, 5, 4, 3, 6],
[3, 7, 7, 1, 3, 0, 2, 0, 2, 7],
[7, 4, 2, 9, 9, 2, 2, 3, 8, 3]])
accuracy: 1.0
AlexNet
- 相当于加强后的 LeNet
- 点燃了深度学习的热潮
- 使用模型来学习特征提取
- 网络架构

- 激活函数换成了 ReLU
- 全连接层使用了丢弃法
VGG
- 更大更好更强更深的 AlexNet
- 将卷积层组件化
- 多个 3x3 padding=1 的卷积层和一个 2x2 stride=2 池化层组成的一个 块
NiN
- 完全使用卷积,使用 1x1 卷积层做通道融合,最后套个全局 AvaragePool/MaxPool 输出
- 1x1 卷积层本质上还是在通道上做全连接层
GoogLeNet
- 更大更好更强更深
- 引入 Inception 块,一个块中使用多个卷积层,最后对通道合并得到输出
- 3x3, 5x5, 1x1 卷积核的优点都占有
以上都是在 LeNet 基础上做加强
批量归一化 [Batch Normalization]
- 对每个输出
$\mu_B = \frac{1}{|B|} \sum_{i \in B} x_i $
$\sigma^2_B = \frac{1}{|B|} \sum_{i \in B} (x_i - \mu_B)^2 + o(0)$
$x_{i+1} = \gamma \frac{x_i - \mu_{B}}{\sigma_B} + \beta $
B 是批量,$\gamma, \beta$ 是需要学习的标准差和均值
- 对每个批量去均值和去方差,并固定到一个新的偏移和新的缩放
- 固定一个批量的均值和方差,学习一个适当的偏移和缩放
- 归一化每一层的输出,下一层的输入
- 可以加快收敛速度
ResNet 残差网络
- 防止网络越深,最后形成的拟合函数还没有中间某层形成的拟合函数效果好
-
每一层的输入等于 $g(x) = \sigma(x) + f(x)$ $\sigma(x)$ 是将 $x$ 的维度变成 $f(x)$ 的维度,这样就可以相加
-
这样也可以防止下层块梯度消失
测试 CIFAR-10
import torch.nn.functional as F
import torch
from torch import nn
import torchvision
from torchvision import datasets, transforms
from torch.utils import data
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.tensorboard import SummaryWriter
# 尝试拿 GPU
def try_gpu(i=0):
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
print(try_gpu())
# 做一些数据增强,预防过拟合
transform = transforms.Compose(
[
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomGrayscale(), # 随机灰度
transforms.ToTensor(), # 转换成 Tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化
]
)
transform1 = transforms.Compose(
[
transforms.ToTensor(),
]
)
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform1)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100, shuffle=True, num_workers=4)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=True, num_workers=4)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
images, labels = next(iter(testloader))
cuda:0
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
def show_images(images, rows, colums, labels):
img = torchvision.utils.make_grid(images, nrow=colums, ncolum=rows)
img = img.numpy().transpose(1, 2, 0)
plt.imshow(img)
plt.show()
labels = np.array([classes[i] for i in labels])
print("labels: \n", labels.reshape((rows, colums)))
def accuracy(y_hat, y):
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.max(axis=1)[1] # 将概率(值)转换成标签
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
show_images(images[:4], 2, 2, labels[:4])
print()
print(f"shape of images: {images.shape}, shape of labels: {labels.shape}")
print()
print(f"accuracy: {accuracy(labels[:4], labels[:4]) / len(labels[:4])}")
!nvidia-smi

labels:
[['bird' 'dog']
['dog' 'dog']]
shape of images: torch.Size([100, 3, 32, 32]), shape of labels: torch.Size([100])
accuracy: 1.0
Wed Mar 2 09:49:59 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |
| N/A 62C P8 32W / 149W | 3MiB / 11441MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
- 有的我都识别不了(
# 一个残差块
class Residual(nn.Module):
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X) # 将 X reshape 成 Y 的形状
Y += X
return F.relu(Y)
block1 = Residual(3, 3) # 通道数没有变化
X = torch.rand(4, 3, 6, 6)
Y = block1(X)
print(Y.shape)
block2 = Residual(3, 6, True, strides=2) # 通道数翻倍,高宽减半
Y = block2(X)
print(Y.shape)
torch.Size([4, 3, 6, 6])
torch.Size([4, 6, 3, 3])
# 定义网络 TrashNet(
class TrashNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.mp = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.res1 = Residual(32, 64, True, strides=2) # 通道翻倍,高宽减半 shape(n, 64, 16, 16)
self.res2 = Residual(64, 64)
self.ap = nn.AdaptiveAvgPool2d((1,1))
self.linarg = nn.Linear(64, 10)
def forward(self, X):
X = X.view(-1, 3, 32, 32) # 用不用无所谓
X = self.conv1(X)
X = self.bn1(X)
X = F.relu(X)
X = self.mp(X)
X = self.res2(self.res1(X))
X = self.ap(X)
Y = self.linarg(X.view(-1, 64))
return Y
net = TrashNet()
X = torch.rand(4, 3, 32, 32)
print(X.shape)
Y = net(X)
Y.shape
torch.Size([4, 3, 32, 32])
torch.Size([4, 10])
loss = nn.CrossEntropyLoss()
num_epochs = 10
lr = 0.9
trainer = torch.optim.SGD(net.parameters(), lr=lr)
device = try_gpu()
net.to(device)
loss = loss.to(device)
for epoch in range(num_epochs):
net.train()
print(f"start train epoch: {epoch + 1}, calculate on {device}")
train_loss = 0.
train_acc = 0.
for n, data in enumerate(trainloader):
X, y = data
X = X.to(device)
y = y.to(device)
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
train_loss += l.sum()
train_acc += (accuracy(net(X), y) / len(y))
train_loss = train_loss / len(trainset) * 100
net.eval()
print(f"start test, calculate on {device}")
test_acc = 0.
test_loss = 0.
with torch.no_grad():
for X_test, y_test in testloader:
X_test = X_test.to(device)
y_test = y_test.to(device)
y_hat = net(X_test)
l_test = loss(y_hat, y_test)
test_loss += l_test.sum()
test_acc += (accuracy(y_hat, y_test) / len(y_test))
test_loss = test_loss / len(testset) * 100
print(f'第{epoch+1}轮 训练集正确率:{train_acc / len(trainset) * 100}% 测试集的正确率:{test_acc / len(testset) * 100}% 训练集损失 {train_loss} 测试集损失 {test_loss}')
start train epoch: 1, calculate on cuda:0
start test, calculate on cuda:0
第1轮 训练集正确率:0.9885200000000047% 测试集的正确率:0.5895999999999999% 训练集损失 0.2613575756549835 测试集损失 1.2496466636657715
start train epoch: 2, calculate on cuda:0
start test, calculate on cuda:0
第2轮 训练集正确率:0.9898200000000045% 测试集的正确率:0.5467000000000002% 训练集损失 0.2557244896888733 测试集损失 1.4415699243545532
start train epoch: 3, calculate on cuda:0
start test, calculate on cuda:0
第3轮 训练集正确率:0.990560000000004% 测试集的正确率:0.5467999999999998% 训练集损失 0.25618138909339905 测试集损失 1.424091100692749
start train epoch: 4, calculate on cuda:0
start test, calculate on cuda:0
第4轮 训练集正确率:0.9916400000000037% 测试集的正确率:0.5634999999999998% 训练集损失 0.24995216727256775 测试集损失 1.371307611465454
start train epoch: 5, calculate on cuda:0
start test, calculate on cuda:0
第5轮 训练集正确率:0.9915600000000033% 测试集的正确率:0.5898000000000001% 训练集损失 0.24579381942749023 测试集损失 1.246112585067749
start train epoch: 6, calculate on cuda:0
start test, calculate on cuda:0
第6轮 训练集正确率:0.9923600000000035% 测试集的正确率:0.6032% 训练集损失 0.23929111659526825 测试集损失 1.1820491552352905
start train epoch: 7, calculate on cuda:0
start test, calculate on cuda:0
第7轮 训练集正确率:0.9925400000000038% 测试集的正确率:0.5604% 训练集损失 0.2401021271944046 测试集损失 1.3554182052612305
start train epoch: 8, calculate on cuda:0
start test, calculate on cuda:0
第8轮 训练集正确率:0.9931000000000033% 测试集的正确率:0.6146% 训练集损失 0.23537792265415192 测试集损失 1.1453310251235962
start train epoch: 9, calculate on cuda:0
start test, calculate on cuda:0
第9轮 训练集正确率:0.9943600000000027% 测试集的正确率:0.5479999999999999% 训练集损失 0.22736258804798126 测试集损失 1.4693257808685303
start train epoch: 10, calculate on cuda:0
start test, calculate on cuda:0
第10轮 训练集正确率:0.994680000000003% 测试集的正确率:0.5175000000000003% 训练集损失 0.22433072328567505 测试集损失 1.4527591466903687
- 不愧是 TrashNet 。。
- 应该是在训练集里学到的一些干扰特征,模型复杂度不够导致无法学习更多特征
可以尝试更深的网络